
从 CausVid 到 Causal Forcing:实时长视频生成中的 Self-Forcing 路线
从 CausVid、Self-Forcing、Self-Forcing++ 到 Causal Forcing,梳理实时、可交互长视频生成中的 few-step autoregressive diffusion 技术路线。
写在前面#
如果只看近两年视频生成模型的效果,最直观的印象往往是:模型越来越大,生成质量越来越高,视频越来越长。但如果把问题换成 实时、可交互、可持续生成的视频系统,事情就会变得复杂很多。
传统高质量视频扩散模型通常依赖 bidirectional attention:模型在去噪某一帧时,可以同时看到过去帧和未来帧。这类设计非常适合离线生成一整段视频,因为全局一致性更容易建模;但它也天然带来三个问题:
- 不能流式输出:模型需要看到完整时间窗口之后,才能统一去噪。
- 交互延迟高:用户中途修改条件、相机、动作或指令时,模型很难即时响应。
- 长视频开销大:随着视频时长增加,双向注意力的计算和显存成本会迅速上升。
因此,CausVid、Self-Forcing、Self-Forcing++ 和 Causal Forcing 这一系列工作,可以被看作是在回答同一个问题:
能否把高质量双向视频扩散模型的能力,迁移到一个 few-step、causal、autoregressive 的生成范式里,从而实现实时、可交互的长视频生成?
这篇文章按照技术演进顺序,梳理这条路线:
CausVid -> Self-Forcing -> Self-Forcing++ -> Causal Forcing1. 问题背景:为什么要从 bidirectional 走向 autoregressive?#
1.1 Bidirectional video diffusion 的优势和瓶颈#
高质量视频扩散模型通常会在一个固定长度的视频窗口上做联合建模。给定一段视频 latent,模型通过多步去噪逐步恢复干净视频。因为注意力是双向的,当前帧可以使用未来帧的信息,所以它在短视频质量、局部一致性和复杂运动建模上通常更强。
但这种范式和实时交互存在天然冲突。
| 维度 | Bidirectional diffusion | Autoregressive diffusion |
|---|---|---|
| 输出方式 | 一次性生成完整窗口 | 逐帧或逐块流式生成 |
| 注意力范围 | 可看过去和未来 | 只能看过去上下文 |
| 首帧延迟 | 通常较高 | 可以显著降低 |
| 交互能力 | 中途改条件较困难 | 更适合在线更新条件 |
| 长视频扩展 | 成本随窗口快速增长 | 可结合 KV cache 和滑动窗口 |
| 主要风险 | 推理慢、交互弱 | exposure bias、误差累积 |
如果目标是类似游戏、数字人、交互式世界模型这样的应用,首帧延迟 和 持续生成速度 往往比离线生成质量更关键。此时,自回归视频生成就变得更有吸引力。
1.2 AR 视频生成的核心难点#
Autoregressive generation 的基本思想很简单:模型先生成前面的视频块,再基于已经生成的上下文继续生成后面的内容。
但它的问题也非常明显:
- exposure bias:训练时模型看到的上下文来自真实视频,推理时看到的上下文来自自己生成的视频。
- 误差累积:早期帧中的小错误会进入历史上下文,并影响后续所有帧。
- architectural gap:如果 teacher 是双向模型,而 student 是因果模型,两者的可见信息和归纳偏置并不一致。
- long-horizon degradation:短视频 teacher 能监督 5s 片段,但无法直接监督 60s、100s 这类长视频生成。
这条技术路线的核心,就是不断缩小这些 gap。
2. CausVid:把双向视频扩散蒸馏到 few-step causal student#
2.1 Motivation#
CausVid 的出发点非常直接:现有高质量视频扩散模型效果很好,但它们通常有两个限制:
- 使用 bidirectional attention,必须看到完整视频窗口;
- 需要较多去噪步数,推理速度不适合实时场景。
所以 CausVid 想做的事情是:把预训练双向视频扩散模型的知识,蒸馏到一个更快的 causal few-step student 中。
这种设定里有两个关键词:
- causal:当前块只能看当前和过去,不能看未来;
- few-step:把原本几十步的扩散采样压缩到少量步数。

2.2 Block-wise Causal Attention DiT#
CausVid 的架构核心是 block-wise causal attention。它不是把每一帧都做成严格的逐帧因果注意力,而是先把视频切成若干 chunk:
- chunk 内部使用双向注意力,保证局部时空一致性;
- chunk 之间使用因果 mask,保证后面的 chunk 不能看到未来 chunk。
假设每个 chunk 的长度为 ,第 个 token 是否能看第 个 token 可以写成:
其中:
- 表示 token 所在的 chunk;
- 当 所在 chunk 不晚于 所在 chunk 时,注意力可见;
- 当前 chunk 不能访问未来 chunk。
这个设计在质量和实时性之间做了折中:chunk 内仍然保留局部双向建模能力,chunk 间则满足流式生成需要。

2.3 Diffusion Forcing:为什么它适合 variable-length generation?#
CausVid 的训练还借鉴了 Diffusion Forcing 的思想。普通视频扩散通常对整个视频窗口使用统一噪声等级,而 Diffusion Forcing 允许不同时间位置处在不同噪声等级上,从而更自然地支持 variable-length generation。
直观来说,它不是只学习“固定长度视频从噪声到干净样本”的映射,而是学习在不同历史可见程度、不同噪声阶段下如何继续推进轨迹。这样做对 AR video generation 很重要,因为推理时模型面对的上下文长度和状态并不总是固定的。
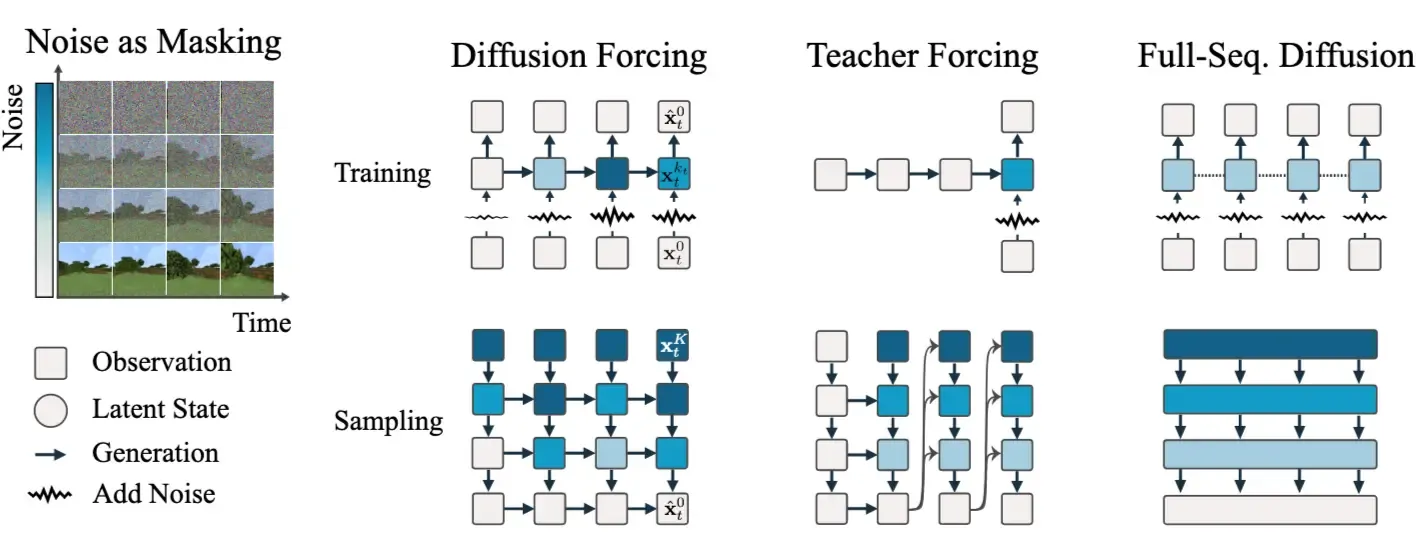
在这个基础上,guide sampling 会把生成轨迹往目标数据分布上拉,使得模型在逐块生成时仍然尽量保持整体轨迹合理。
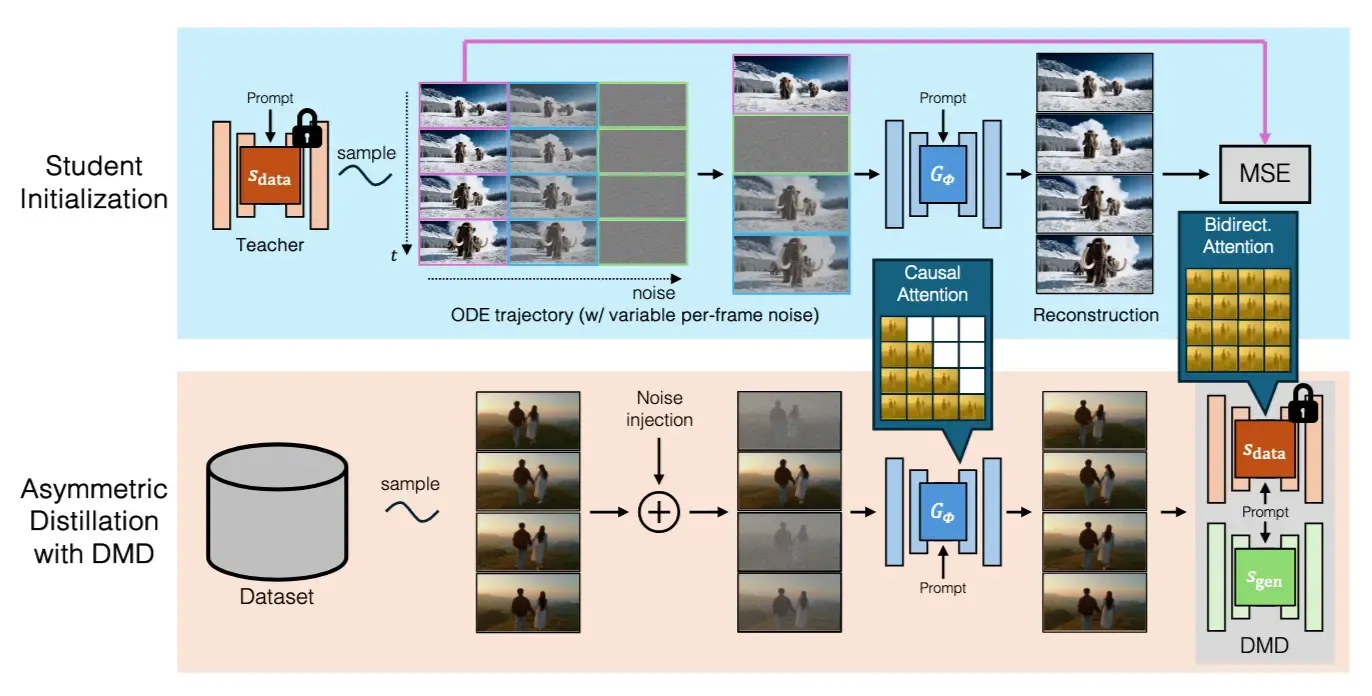
2.4 Student Initialization:用 ODE trajectory 缓解架构差异#
直接用双向 teacher 去训练 causal student,问题很大。因为 teacher 可以看未来,而 student 不可以看未来,两者架构能力不对称。CausVid 因此先做一个轻量初始化。
大致流程是:
- 从标准高斯分布采样初始噪声;
- 使用预训练双向 teacher 和 ODE solver,模拟从噪声到干净样本的反向扩散轨迹;
- 从完整 ODE trajectory 中抽取与 few-step student 对齐的时间步;
- 用 MSE 让 student 拟合这些中间状态或预测结果。
可以把这一步理解为:先给 causal student 一个比较合理的采样轨道,避免后续蒸馏一开始就发散。
2.5 Asymmetric DMD Distillation#
完成初始化后,CausVid 使用 asymmetric DMD distillation 进一步训练 student。
这里的 asymmetric 指的是:
- teacher 是 bidirectional diffusion model;
- student 是 causal few-step generator;
- teacher 和 student 的结构、可见上下文和推理步数都不相同。
DMD,即 Distribution Matching Distillation,核心思想是用 score difference 来近似分布匹配的梯度。直观地说,它不是简单要求 student 逐像素模仿 teacher 输出,而是要求 student 生成样本的分布逐渐靠近真实数据分布。
可以用下面的近似梯度理解:
其中:
- 是 student generator;
- 是对 student 生成结果加噪后的样本;
- 是来自真实数据分布或 teacher 的 score;
- 是拟合 student 当前生成分布的 score;
- 两个 score 的差值给出“往真实数据分布靠近”的方向。
在训练流程上,可以这样理解:
- student 先快速生成一段视频;
- 对生成视频重新加噪;
- 训练一个
s_gen去拟合 student 当前生成分布; - 用
s_data - s_gen的差异把梯度传回 student。
2.6 推理:KV Cache 加速流式生成#
一旦模型改成 causal 结构,推理时就可以自然使用 KV cache。对于每个新生成的视频块,过去上下文的 key/value 不需要反复重算,而是可以缓存下来供后续块复用。
这也是 AR 范式相比 bidirectional 范式的重要工程优势:
只要上下文读写逻辑设计合理,长视频生成可以从“重复处理整段历史”变成“增量生成新内容”。

2.7 小结:CausVid 解决了什么,还留下什么?#
CausVid 的意义在于,它证明了从高质量双向视频扩散模型蒸馏出实时 causal few-step 模型是可行的。
但它仍然保留了一个关键问题:训练中的上下文分布和推理中的上下文分布并不完全一致。训练阶段模型仍然可能依赖比较“干净”的上下文,而推理阶段上下文来自模型自己生成的历史帧。这个问题,就是 Self-Forcing 重点处理的 exposure bias。
3. Self-Forcing:训练时就让模型看自己生成的上下文#
3.1 Motivation#
Teacher Forcing 和 Diffusion Forcing 的共同问题是:训练时的 context 往往来自真实数据或加噪真实数据,而推理时的 context 来自模型自己生成的内容。
这会导致典型的 train-test gap:
训练:真实上下文 -> 预测下一帧
推理:模型生成的上下文 -> 预测下一帧Self-Forcing 的回答很直接:
既然推理时模型只能看自己生成的历史,那训练时也应该让模型看自己滚出来的历史。
这就是 Self-Forcing 的核心思想。
3.2 Teacher Forcing、Diffusion Forcing 和 Self-Forcing 的区别#
| 方法 | 训练时上下文 | 主要优点 | 主要问题 |
|---|---|---|---|
| Teacher Forcing | Ground Truth 历史帧 | 训练稳定、监督直接 | 推理时上下文变成模型输出,存在 exposure bias |
| Diffusion Forcing | 带噪真实轨迹,不同帧可有不同噪声等级 | 支持 variable-length generation | 仍未完全消除 train-test context gap |
| Self-Forcing | 模型自己去噪得到的干净上下文 | 训练和推理更一致 | 需要控制显存和梯度传播成本 |
Self-Forcing 不是简单把 rollout 拉长,而是把 self-rollout 放进训练过程:模型一帧一帧生成,把自己生成的 KV 写入缓存,再基于这个缓存继续生成后续帧。
3.3 Self-Forcing Training:只在随机去噪步保留梯度#
如果对整个自回归生成链条完整反传,显存开销会非常高。假设生成 10 帧,每帧 4 个去噪步,如果全部保留计算图,就需要保留 40 次网络前向的中间状态。
Self-Forcing 的关键技巧是:随机采样一个去噪步 ,只在这个步上保留梯度,其余步骤都作为 no-grad rollout。

简化伪代码如下:
# X_theta: student rollout outputs
# cache: rolling KV cache
# T: total denoising steps
# s: randomly sampled training step
X_theta = []
cache = empty_cache()
s = sample_uniform(1, T)
for i in range(num_frames):
x = sample_gaussian_noise()
for j in reversed(range(1, T + 1)):
if j == s:
# keep gradient only at step s
x0_hat = student(x, timestep=j, cache=cache)
X_theta.append(x0_hat)
else:
# rollout context without storing full computation graph
with no_grad():
x = student_denoise_step(x, timestep=j, cache=cache)
with no_grad():
kv = extract_kv_features(x0_hat)
cache.append(kv)
loss = distribution_matching_loss(X_theta, real_video)
loss.backward()这种训练方式有两个重要效果:
- 模型看到的是自己生成的上下文,因此训练分布更接近推理分布;
- 显存成本可控,因为大部分 rollout 过程不保留梯度。
3.4 为什么这能缓解 exposure bias?#
Exposure bias 的本质是:模型训练时没有学会如何处理自己犯下的小错误。
Self-Forcing 中,历史上下文不是 ground truth,而是模型自己一步步生成出来的。因此,如果模型在前面帧里产生轻微偏差,后续训练就会真实地暴露在这种偏差下。模型被迫学习如何在“不完美历史”上继续生成,而不是只在理想上下文上预测下一帧。
这和语言模型中的 scheduled sampling 有一点类似,但在视频扩散里更复杂,因为每一帧还涉及多步去噪、时空注意力和 KV cache 状态。
3.5 Autoregressive Inference:训练和推理保持一致#
推理阶段和训练阶段的差别主要是去掉梯度控制:
- 初始化空的输出序列和 KV cache;
- 对每一帧从高斯噪声开始完整去噪;
- 生成当前帧后,把它的 KV 特征写入缓存;
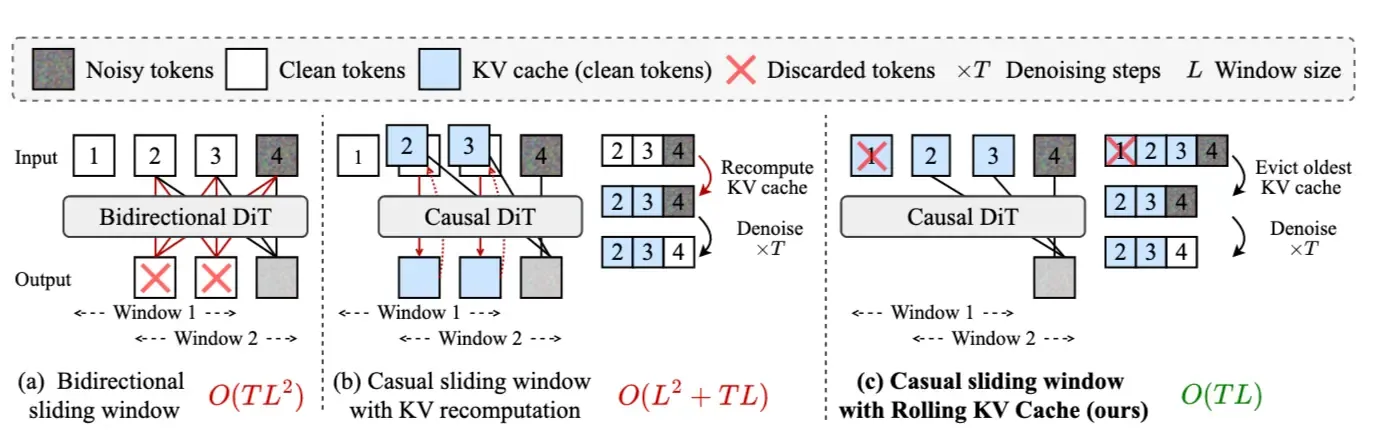
- 缓存满了之后,移除最老的 KV,只保留最近 帧上下文;
- 重复这个过程,得到任意长度的视频。
这就是 Rolling KV Cache。
3.6 Rolling KV Cache:长视频生成的关键工程结构#
如果 KV 一直累积,显存和内存都会随视频长度增长。Rolling KV Cache 的做法是把上下文变成固定长度滑动窗口:
生成第 100 帧时,只保留第 80 到 99 帧的 KV
生成第 101 帧时,只保留第 81 到 100 帧的 KV它的优势是显而易见的:
- 内存开销不再随总视频长度无限增长;
- 历史上下文不需要反复重算;
- 训练和推理可以使用几乎一致的缓存读写逻辑。
但这里有一个容易忽略的问题:如果训练时模型总能看到第一帧,而推理长视频时第一帧最终会被 rolling cache 移出窗口,就会出现新的分布失配。Self-Forcing 的处理思路是:训练时就限制注意力窗口,让模型提前适应“首帧不可见”的情况。
4. Self-Forcing++:让短视频 teacher 继续监督长视频 student#
4.1 Motivation#
Self-Forcing 已经缓解了 exposure bias,但它仍然面对一个长视频问题:
teacher 只能处理短视频窗口,例如 5s;student 推理时却要生成 60s、100s 甚至更长。
这会导致两类失配:
- 时序长度失配:训练时只覆盖短 horizon,推理时进入长 horizon;
- 监督范围失配:超过 teacher 能处理的窗口后,student 缺少有效监督。
一个重要观察是,长视频生成往往不是立刻崩坏,而是逐渐退化:运动变慢、细节变糊、时序稳定性下降。这意味着错误可能是可纠正的。Self-Forcing++ 的核心,就是把短视频 teacher 的局部监督能力重新包装成适合长视频训练的信号。
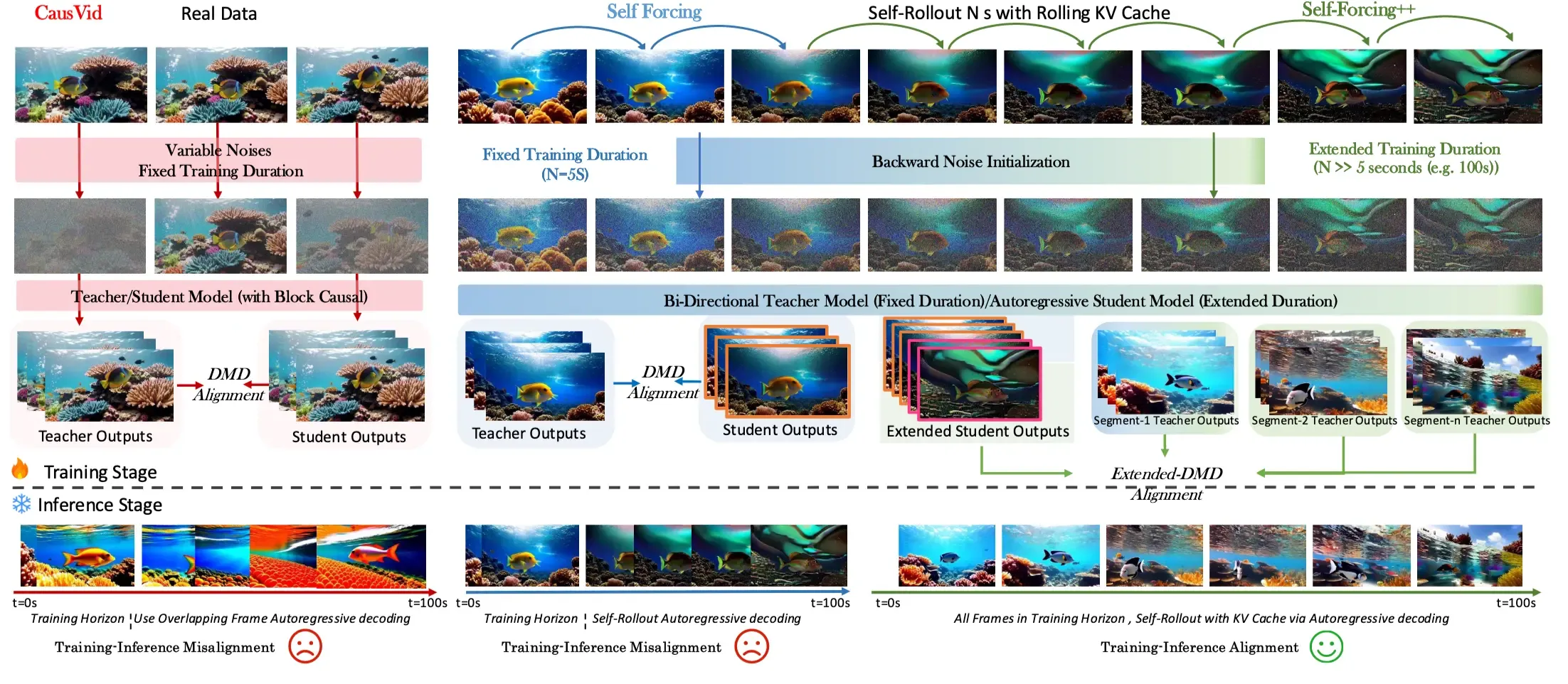
4.2 反向噪声初始化:从已有 rollout 出发,而不是从独立噪声出发#
普通 DMD 训练通常从随机噪声开始。但在长视频生成中,后续片段的噪声状态应该和前面已经生成的内容存在时序关系。否则,训练目标和真实 long rollout 条件并不一致。
Self-Forcing++ 的做法是:
- 先用 rolling KV cache 做一次长程 autoregressive rollout,得到 帧视频;
- 对这段已经生成、可能已经退化的视频重新加噪;
- 在这个带有历史上下文的含噪状态上,让 teacher 和 student 预测分布并计算训练信号。
对应公式可以写成:
其中 来自 student 的 rollout,而不是独立采样的真实短片段。也可以把一步去噪关系写成:
直观地说,它不再假设每个训练样本都是孤立短视频,而是主动把 student 在长程生成中遇到的状态纳入训练。
4.3 Extended DMD:Sliding Window Supervision#
teacher 虽然不能直接处理 100s 视频,但它知道什么样的 5s 片段是高质量视频。因此,Self-Forcing++ 在 student 的长 rollout 上随机截取一个 teacher 能处理的窗口,让 teacher 对这个局部窗口提供监督。
设:
- student rollout 总长度为 ;
- teacher 可处理窗口长度为 ;
- 起始位置 ;
- 表示从长 rollout 中取出的第 个窗口。
Extended DMD 可以理解为在所有可能短窗口上做平均分布匹配:
进一步近似为:
这个公式的直觉非常重要:
- teacher 不需要理解完整 100s 视频;
- teacher 只需要判断局部窗口是否像一个高质量短视频;
- student 通过在长 rollout 上反复接受局部窗口监督,逐渐改善长程生成质量。
4.4 训练和推理都使用 Rolling KV Cache#
Self-Forcing++ 进一步强调:训练和推理都应该使用 rolling KV cache。这样可以避免训练时使用完整历史、推理时只能使用滑动窗口的失配。
这点看似工程细节,实际上非常关键。对于长视频生成,cache 策略本身就是模型分布的一部分。如果训练和推理的缓存可见范围不一致,模型就会学到错误的时序依赖。
4.5 GRPO 和光流奖励:抑制长程退化#
Self-Forcing++ 还引入 GRPO(Group Relative Policy Optimization)思路,用相对奖励进一步优化长视频的时序质量。笔记中提到的奖励信号基于 optical flow magnitude,可以写成:
这个奖励的直觉是:通过约束相邻帧之间的运动变化,减少突变和闪烁。
不过工程上需要注意:如果只惩罚光流大小,模型可能倾向于生成过于静止的视频。因此更稳妥的做法通常是把它作为相对奖励或辅助奖励,与文本一致性、图像质量、运动合理性等信号共同使用。GRPO 的相对奖励形式可以在一定程度上缓解 reward hacking。
4.6 小结:Self-Forcing++ 的核心不是“更长 rollout”,而是“让短 teacher 监督长 student”#
Self-Forcing++ 最重要的贡献可以概括为一句话:
把 teacher 的短窗口判别能力,转化成对 student 长程 rollout 的局部监督。
这让短视频 teacher 在不直接处理长视频的情况下,仍然能够参与长视频生成训练。
5. Causal Forcing:重新审视 ODE initialization#
5.1 Motivation#
Causal Forcing 的切入点和 Self-Forcing 不完全一样。
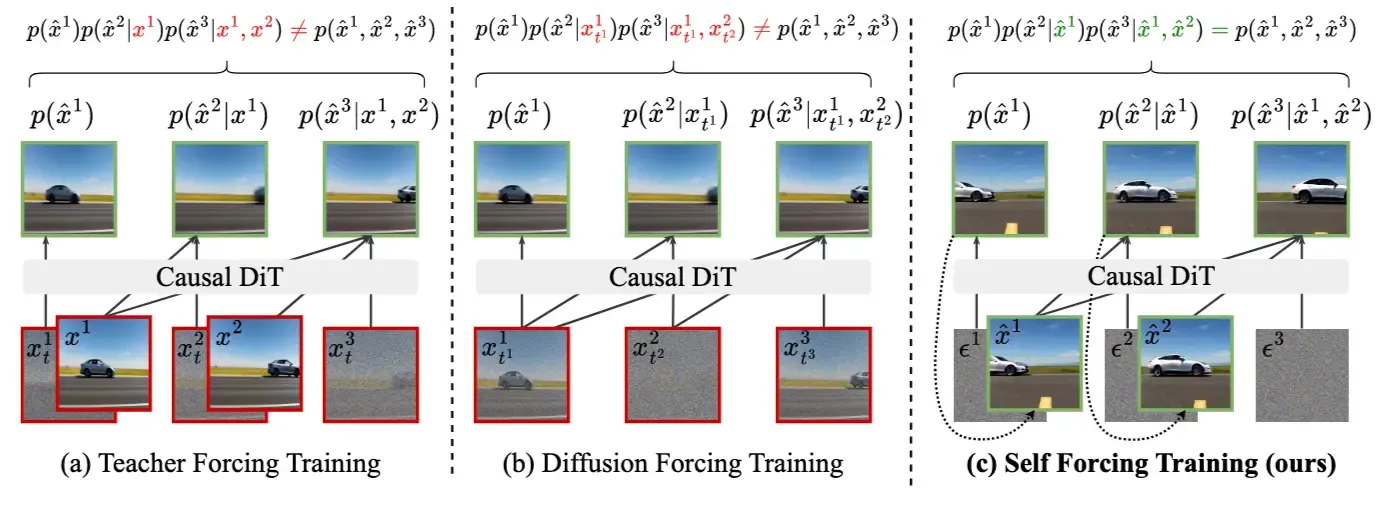
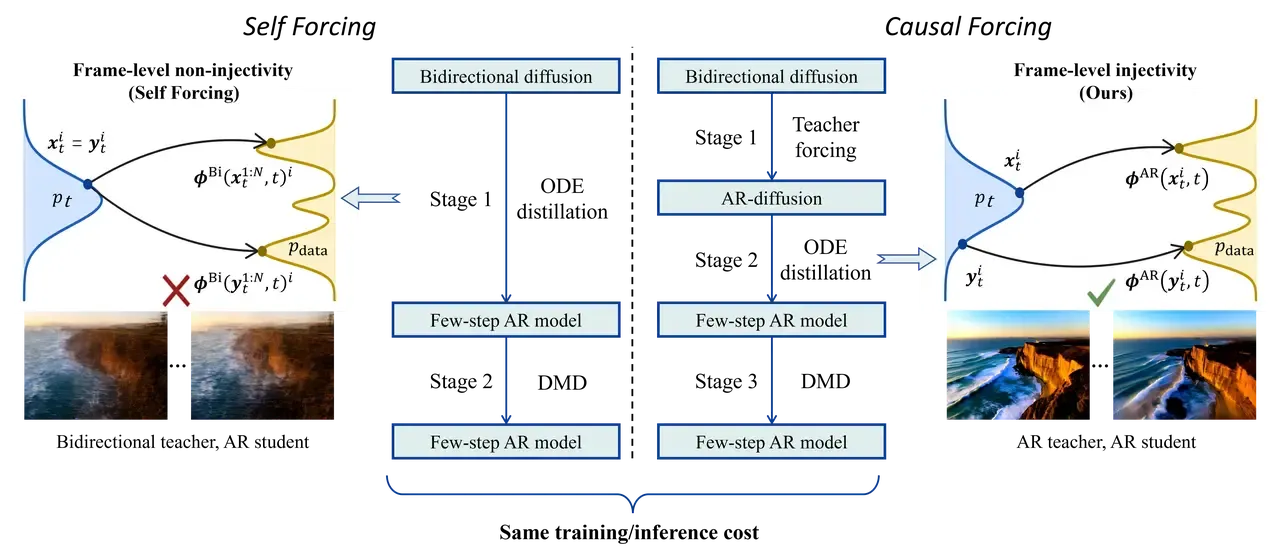
Self-Forcing 主要强调 DMD 阶段的 exposure bias:训练时应该让 student 看自己生成的历史。而 Causal Forcing 认为,前面工作对 DMD 的关注较多,但 student initialization 本身也存在问题。
具体来说,CausVid / Self-Forcing 中的初始化往往依赖 bidirectional diffusion teacher 的 ODE trajectory。但 student 是 causal AR 模型,它无法访问未来信息。用一个 bidirectional teacher 直接提供 ODE 轨迹,仍然会留下 architectural gap。
Causal Forcing 的观点是:
与其直接用 bidirectional teacher 初始化 causal student,不如先训练一个原生 AR diffusion teacher,再用这个 AR teacher 产生 causal ODE 监督。
5.2 三阶段训练流程#
Causal Forcing 可以拆成三步:
-
Stage 1:训练 AR diffusion teacher
先用 teacher forcing 训练一个多步生成的 autoregressive diffusion model。这个模型不是 few-step student,而是一个更强、更慢、但结构上已经 causal 的 teacher。 -
Stage 2:Causal ODE initialization
用 Stage 1 得到的 AR diffusion teacher 构造 causal ODE trajectory,再训练 few-step AR student。因为 teacher 和 student 都是 causal,这一步可以显著减小架构不匹配。 -
Stage 3:Self-Forcing-style DMD
以 Stage 2 的 few-step AR student 作为初始化,再继续做类似 Self-Forcing 的 self-rollout DMD 训练。
5.3 和 Self-Forcing 的关系#
Causal Forcing 并不是否定 Self-Forcing,而是在它前面补了一块更合理的初始化路径。
| 对比点 | Self-Forcing | Causal Forcing |
|---|---|---|
| 主要关注 | DMD 训练阶段的 exposure bias | ODE initialization 阶段的 architectural gap |
| teacher 类型 | 通常来自 bidirectional video diffusion | 先训练 AR diffusion teacher |
| 初始化方式 | 用 bidirectional teacher 的 ODE trajectory 初始化 causal student | 用 causal AR teacher 的 ODE trajectory 初始化 few-step student |
| 后续训练 | self-rollout + DMD / SiD / GAN loss | causal ODE 初始化后继续 Self-Forcing-style DMD |
一句话总结:
Self-Forcing 解决“训练时看谁”的问题,Causal Forcing 解决“初始化时向谁学”的问题。
6. 一张表看完整技术演进#
| 方法 | 核心问题 | 关键技术 | 主要收益 | 仍需注意 |
|---|---|---|---|---|
| CausVid | 如何把双向视频扩散变成实时 causal few-step 模型 | Block-wise causal attention、ODE initialization、Asymmetric DMD、KV cache | 证明实时 AR video diffusion 路线可行 | 仍存在 train-test context gap |
| Self-Forcing | 如何缓解 exposure bias | Self-rollout training、随机去噪步保梯度、Rolling KV Cache | 训练和推理上下文更一致 | 长视频 teacher 监督范围有限 |
| Self-Forcing++ | 如何让短视频 teacher 监督长视频 student | 反向噪声初始化、Sliding Window DMD、训练/推理统一 rolling cache、GRPO | 改善 100s 级长视频退化 | 奖励设计和长程稳定性仍复杂 |
| Causal Forcing | 如何缓解 bidirectional teacher 和 causal student 的初始化 gap | 先训练 AR diffusion teacher,再做 causal ODE initialization | 更合理的 few-step causal student 初始化 | 训练流程更长,成本更高 |
7. 总结#
从 CausVid 到 Self-Forcing,再到 Self-Forcing++ 和 Causal Forcing,这条路线的演进可以概括为三个关键词:
- Causalization:把双向视频扩散模型改造成可流式的因果生成模型;
- Self-rollout:训练时让模型使用自己生成的上下文,减少 exposure bias;
- Long-horizon supervision:把短视频 teacher 的能力扩展到长视频 student 的训练中。
如果把这条路线放到更大的生成模型趋势里看,它其实是在尝试把视频生成从“离线渲染一段 clip”推进到“在线运行一个动态世界”。这也是为什么 AR diffusion、KV cache、few-step distillation 和 self-forcing 会变得越来越重要。